|
|
*********************************************************************
该项目已经发布到github上了,有需要的朋友可以点击这里获取
*********************************************************************
第一部分 简介
创作原因
最近在学校的跳蚤群里看到一位同学在找人帮忙做期末大作业,当时看到她消息里大写的“求代写作业!”我心中闪过一丝不屑,心想:像我这种好学生(bushi)怎么可能会帮别人写作业呢对吧?本打算如往常一般将消息快速划过,但眼角残留的一点点余光瞥到的剩余内容却吸引住了我:
几个关键词引得我浮想联翩

首先是看到豆瓣和情感分析,曾经看过几个网络爬虫教程的我对这个网站可谓再熟悉不过,它也算是初学爬虫者的老朋友了,就像新手打开王者荣耀后第一个和你打招呼的准是妲己 ~ 。而情感分析眼熟则是因为我之前帮学院的老师做科研项目时曾接触过,算是NLP领域常见的任务,自己也比较熟悉。
再一看要用的语言,哟,这不是信管人的初恋编程语言python吗? 看到这几个关键词,我顿时来了兴趣,便接着把消息看了下去,最后她居然还有个可视化的要求,这简直就是当代数据处理一条龙啊!从数据的采集,再到数据的分析,再到最后的数据展示,全齐了。而我又一直想找个机会把自己之前学过的零零散散的技术全部串起来,却苦于没有这样的机会。

不过现在机会来了,还可以顺便赚点外快改善生活......于是我一脚将心中的那一丝丝不屑踹的老远,告诉自己大家都是校友,难道不应该发挥校园互帮互助的友好精神吗?于是乎,我便找到这位求助的新传同学,向她问清楚了作业要求,如下:

看上去还算比较简单,虽然有些地方的要求不是很明确,不过也给了我发挥的空间,而且听上去感觉像是不太懂这方面的小白捏哈哈哈。
那么接下来就可以开工咯,早点干完活早点买好吃的
第二部分 正文
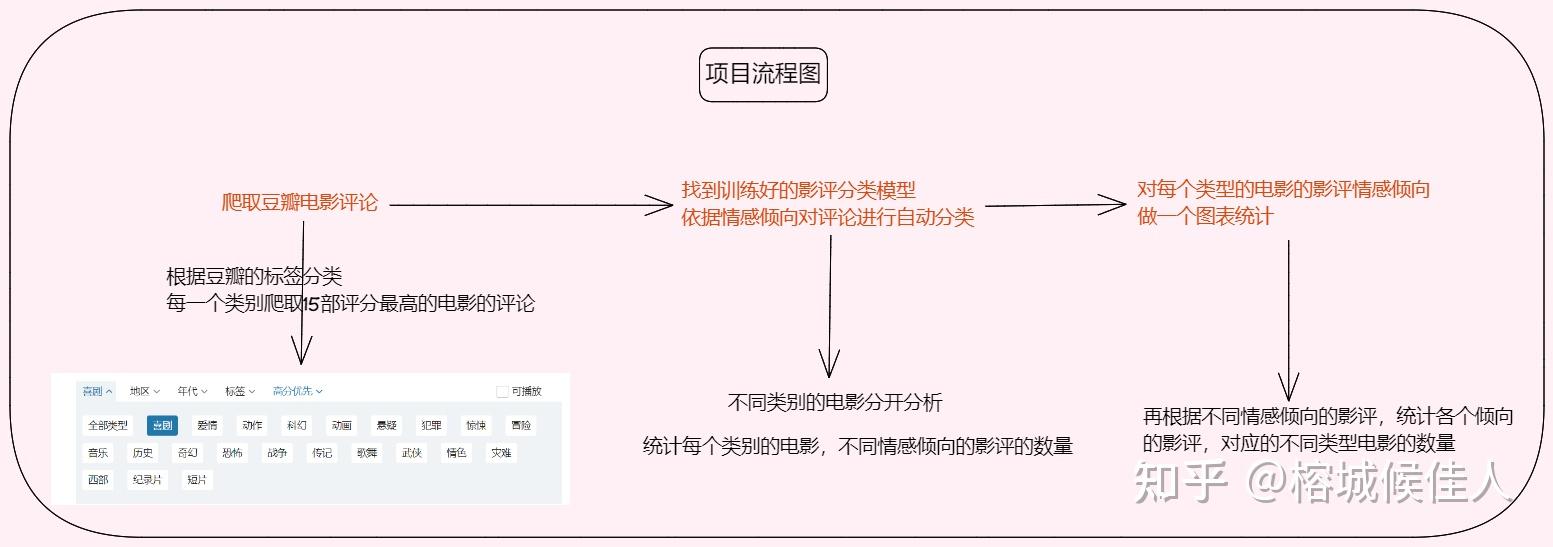
(一)、整体思路
做啥都得先规划好不是,不然做到一半发现自己离目标越来越远那就不好了。。。而这个任务的流程不算太复杂,可以简化为三个大步骤:
(二)、爬取豆瓣电影评论
第一步爬虫。额,说实话这东西我花费的时间是最久的。(别问,问就是之前的经验全都忘记了,也没注意做问题的记录......导致一些概念忘得精光,在阅读网站和爬取数据的时候那叫一个心酸呐QAQ)下面分步骤讲解。
1. 分析网站(不同类型电影的主网站)
打开豆瓣官网,找到豆瓣电影
进去以后目标明确(目标是爬取所有类型电影,各自排名前15的电影200条影评,总计是30*15=450部影片,评论条数为450*200=90000条),直奔排行榜。

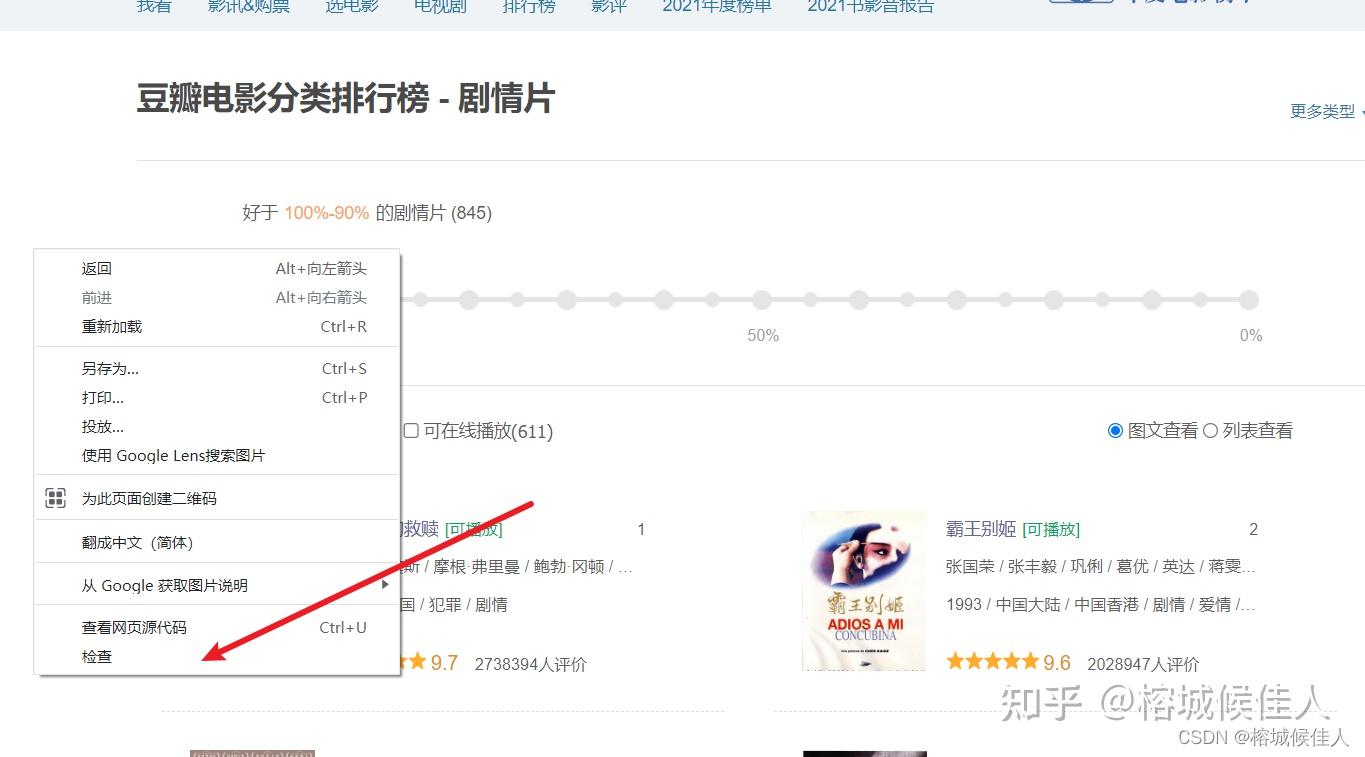
接下来就以剧情这个类型为例进行介绍。我们首先右键点击检查,打开网络开发者工具
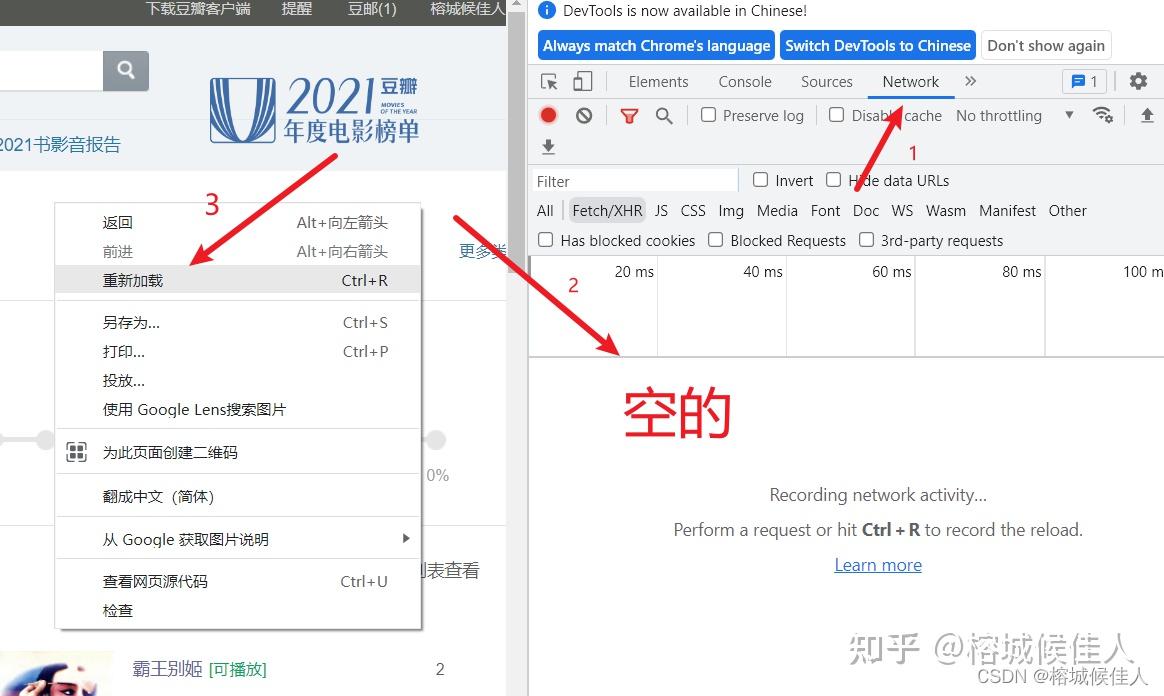
进去以后点击network,并重新加载刷新数据
可以看到里面的数据使用了Ajax进行展示(向下滑动滚轮数据会不断增加),考虑应该是用json格式存储
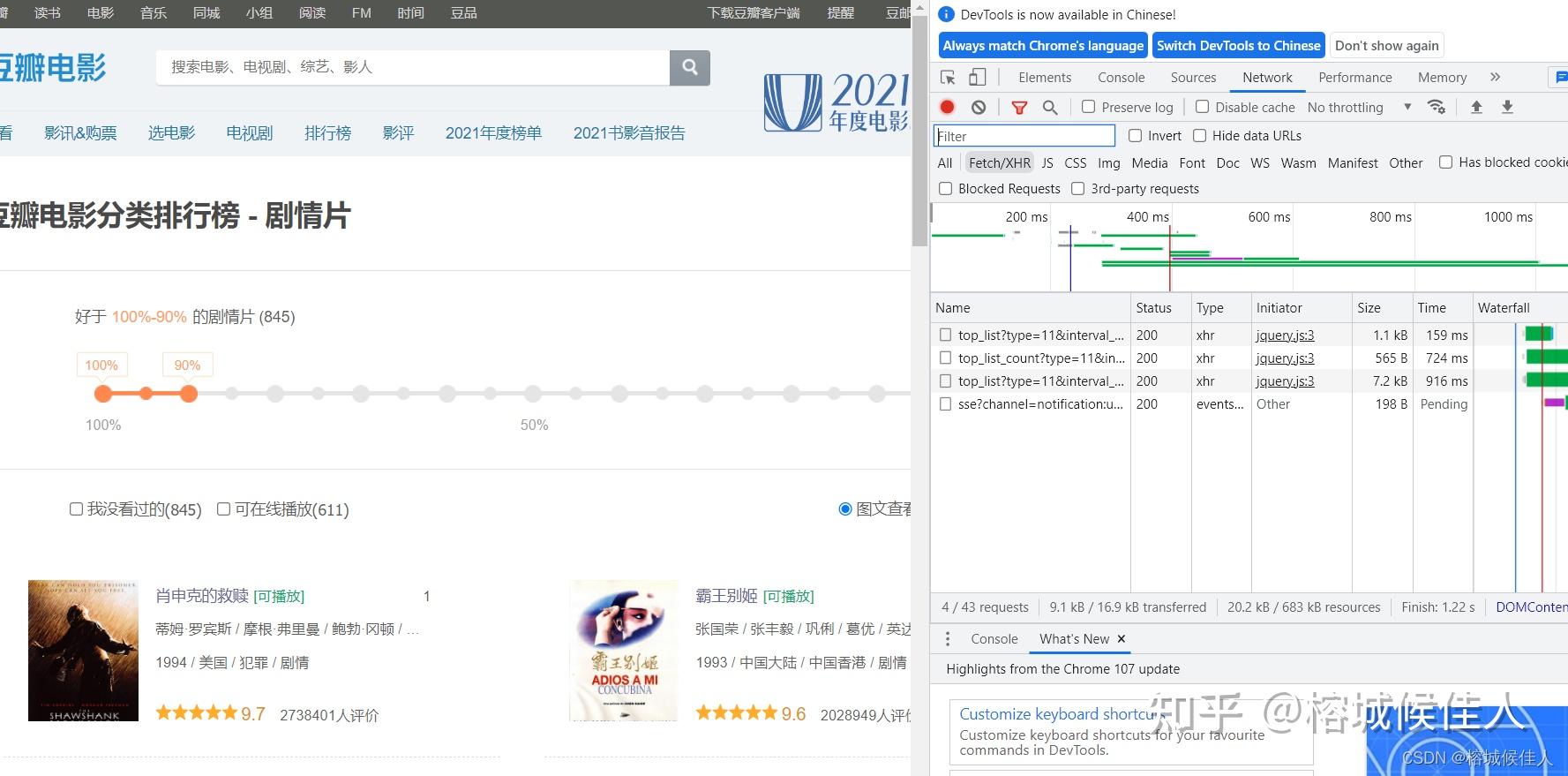
第一次刷新四条数据
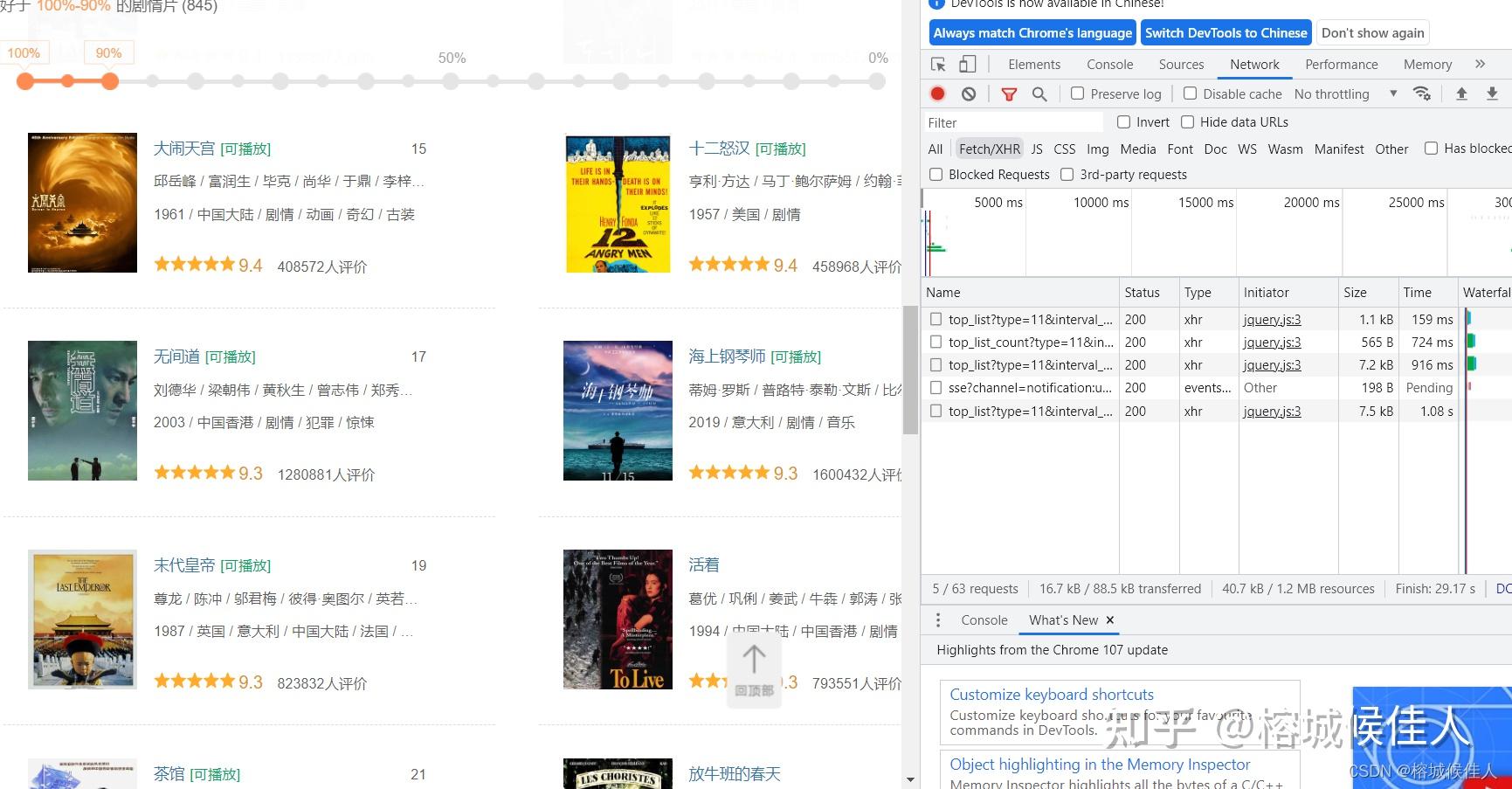
第二次刷新多了一条数据
点开其中一条观察,可以观察到参数设置的情况。
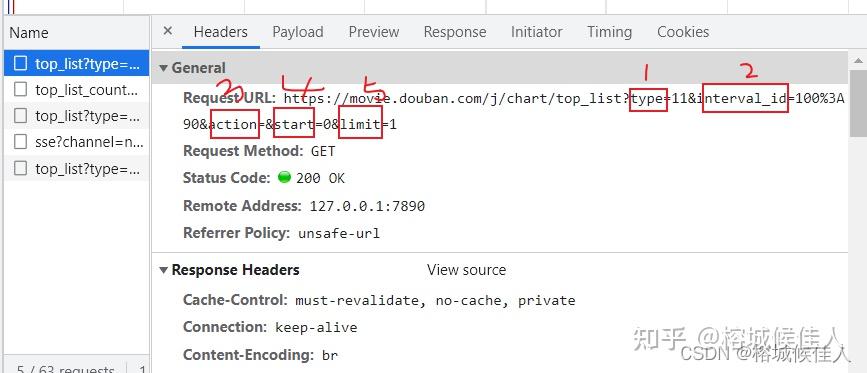
不难理解各个参数的含义:
1.type:电影类型的代号
2.interval-id:某种固定的符号(好吧猜不到,但是多观察几条数据可以发现都是一样的,也就无伤大雅啦)
3. action:都为空,同样不用去管
4. start:值得是从哪部电影开始,0打头
5. limit:一次最多展示几部电影(可以发现都是20)
再看数据部分。


发现确实是json格式存储的,那么在获取的时候就可以使用json方法。而且可以观察到里面的数据有各个电影的url和类型,而这正是我们后面爬取影评所需要的(其实最主要的电影的url)
2. 分析网站(电影影评所在的网页情况)
上面是对不同类型的电影所在网页的分析,但我们的最终目的是获取每一部电影的影评,因此还需要对影评所在的网页进行分析。
下面以《肖申克的救赎》为例,点击电影链接,找到全部评论,并点击
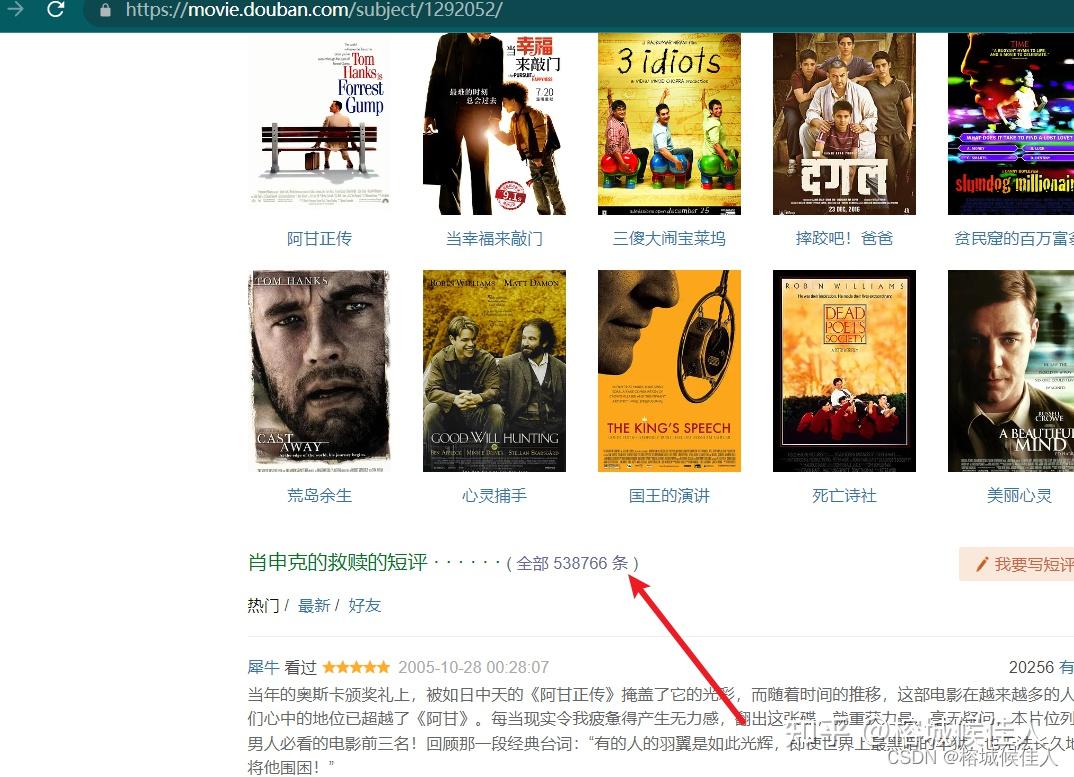
进去以后下拉到最底下可以发现有“首页”、“前页”、“后页”三个按钮,分别点击并观察网页的rul你会发现其中的奥秘的。
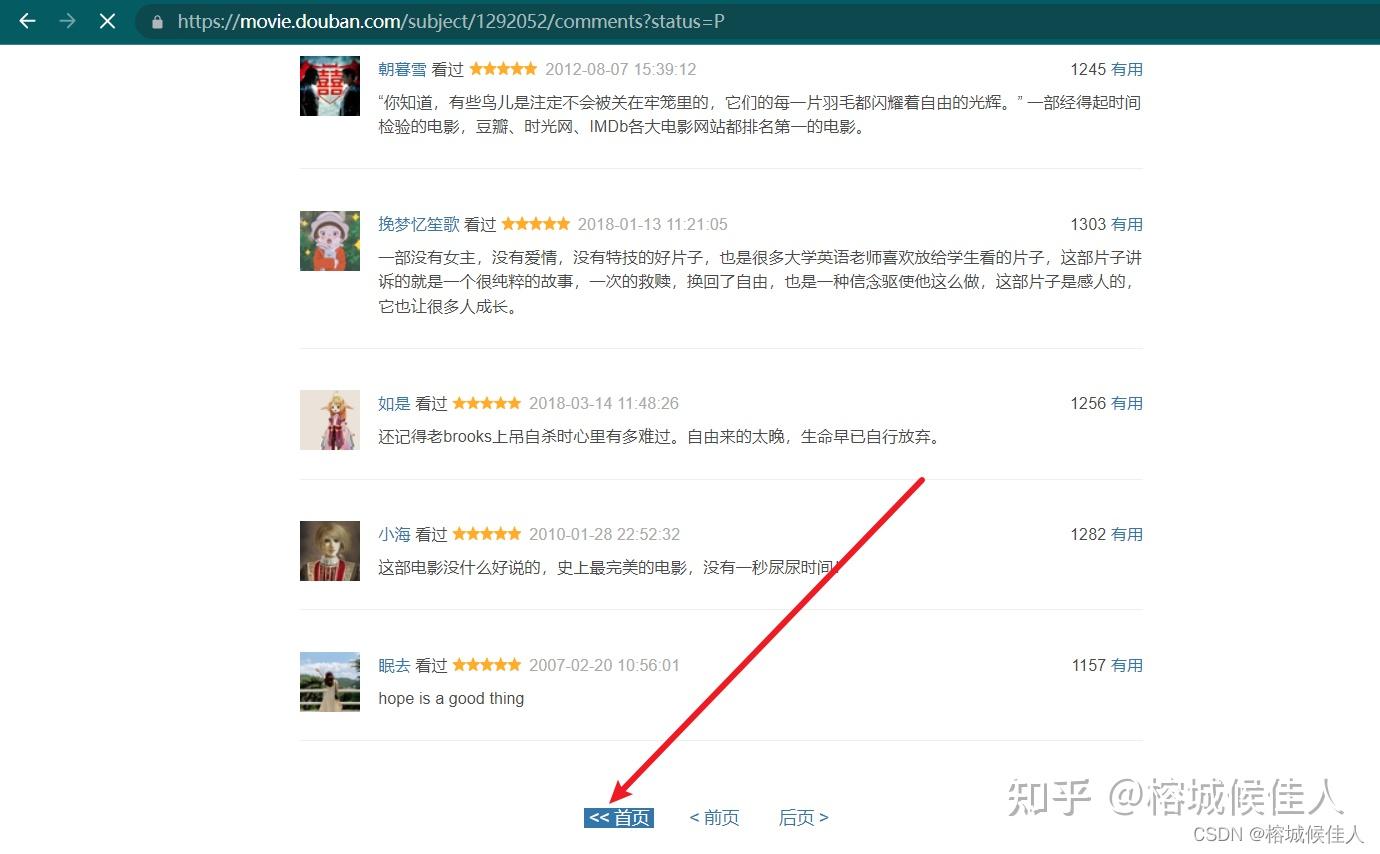
点击进入首页
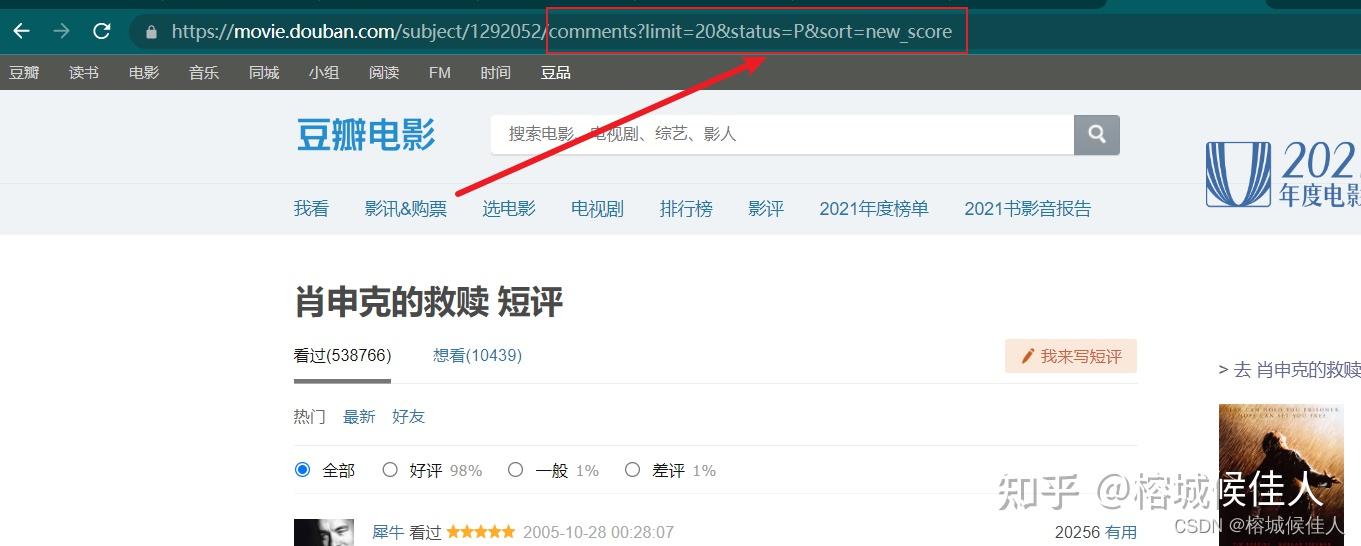
观察首页url
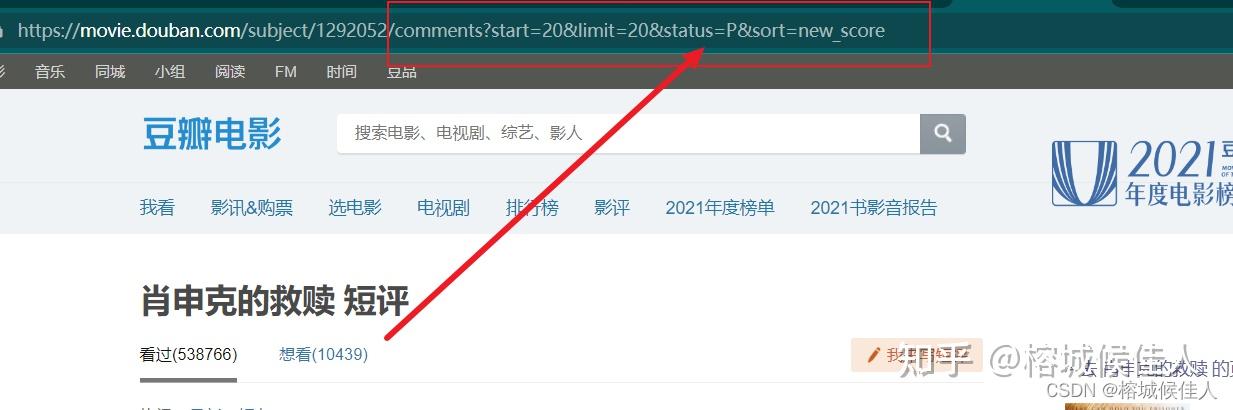
观察其他页面的url
首页url:https://movie.douban.com/subject/1292052/comments?limit=20&status=P&sort=new_score
其他页面url:
https://movie.douban.com/subject/1292052/comments?start=20&limit=20&status=P&sort=new_score
通过两者的对比,可以发现两个规律:
a.首页url中少了start参数
b.要获得同一部电影影评的其他页面的url,只需要修改start参数即可!!!
那么到现在,我们就完成了对全部网页的分析,接下来就是激动人心的代码部分了(doge,懂得都懂)

3. 根据网页结构,编写爬虫代码
首先需要强调的是,在爬取的过程中还是很有几个坑的,下面就让我这个刚刚从坑里爬出来的人给大家讲讲如何避坑吧。
(一)导入要用的包和模块,这里采用了bs4和python自带的requests包
备注:没有安装bs4的uu在命令行(cmd)中执行下面的命令就可以了(后面那一串是镜像源加速用的),或者参考这篇怎么安装Python的bs4包博客也行。
pip install bs4 -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# coding: utf-8
# 作者(@Author): 榕城候佳人
# 创建时间(@Created_time): 2022/11/7 19:02
# 修改时间(@Modified_time): 2022/11/17 17:30
"""
爬取豆瓣电影评论
"""
import requests
from bs4 import BeautifulSoup
import os
import time
(二)爬取前的一些准备工作
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
# 主网页
url = 'https://movie.douban.com/chart'
# 设置代理,
proxies = {
# 'http': '172.30.6.14:8880',
# 'http': "36.152.44.96:5000", # 百度ip
# "http": '111.30.144.71:5000', # QQip
# 'http': '47.103.24.173:5000', # b站ip
# 'http': ' 192.168.210.53:5000', # 本地ip
# 'http': '60.205.172.2:5000', # CSDNip
'http': "49.233.242.15:5000", # 豆瓣ip(doge,想不到吧)
# 'http': '120.233.21.30:5000', # 微信ip
# 'http': '103.41.167.234:5000', # 知乎ip
# 'http': '39.156.68.154:5000', # hao123ip
# 'http': '36.152.218.86:5000', # 凤凰网ip
# 'http': '151.101.78.137:5000', # 人民网ip
# 'http': '221.178.37.218:5000', # 中国网ip
关于准备工作,其实就是防止反爬虫的一些方法,如UA伪装,设置代理等等。这些其实还是有挺多讲究的,感兴趣的朋友可以自行谷歌百度。我这里的代码是根据自己平时的经验写的,特别是在设置代理这一块算是我的一个小发现吧:
大家都知道有些网站如果被频繁的访问,是有可能把访问主机的ip给封掉的,而最常见的解决办法就是设置代理ip。我当时也上网查了一些,但都感觉比较麻烦。于是乎我急中生智,想到ping其他网站来获取他们ip的方式试图蒙混过关,结果表明还真的可以hhh。尤其是我用ping豆瓣得到的ip,连续爬取直到全部获取主动结束。

(三)正文部分,先获得整个网页,处理好编码问题并创建bs对象response
# 解决乱码问题
response = requests.get(url, headers=headers, proxies=proxies)
response.encoding = 'utf-8'
# 获得不同类型电影的url
response = response.text
main_soup = BeautifulSoup(response, 'html.parser') (四)去网页源代码中找到不同类型电影的url
dif_movies = main_soup.select('#content > div > div.aside > div:nth-child(1) > div')
movie_types = [] # 存储不同类型电影的页面url
urls = dif_movies[0].find_all('a')
# 获得不同类型电影的代号和名称
for url in urls:
param = url['href']
index1 = param.find("&type=")
index2 = param.find("&interval_id=")
type_num = param[index1 + 6:index2] # 电影类型代号
type_name = param[20:index1] # 电影类型名称
movie_types.append((type_num, type_name))我们首先要得到每个类型的电影的总的网页,再去从每个总的网页中爬取前20部电影。因此这里最终用movie_types这个元组来分别存放每部电影的代号(上面分析过的,每个类型的电影有不同的代号,如11,30等等)和名称。

(五)进入大循环,获得每个类型中15部电影的url
# 爬取不同类型电影中前15的电影评论
for type, movie_class in movie_types:
print(f&#34;{&#39;*&#39; * 20}开始爬取->{movie_class}<-类型的电影{&#39;*&#39; * 20}&#34;)
movie_url = &#39;https://movie.douban.com/j/chart/top_list&#39;
param = {
&#34;start&#34;: &#34;0&#34;,
&#34;limit&#34;: &#34;20&#34;,
&#34;type&#34;: f&#34;{type}&#34;,
&#34;interval_id&#34;: &#34;100:90&#34;,
&#34;action&#34;: &#34;&#34;,
}
response = requests.get(movie_url, headers=headers, params=param, proxies=proxies)
time.sleep(1) # 限制请求时间,防止被封ip
response.encoding = &#39;utf-8&#39;
movie_data = response.json()
# 存放这个类型下前二十的电影的网址和名称
urls = []
for data in movie_data:
urls.append((data[&#39;url&#39;], data[&#39;title&#39;]))使用的是get方法,在参数中设置电影的类型type,然后在获得的数据中根据键“url” 和“title”获得每部电影的url和名称
(六)在本地创建不同电影类型的目录
# 创键对应的电影类型目录
path = os.path.join(&#34;E:\PycharmProjects\Web项目\新传数字人文项目&#34;, movie_class)
path = path.strip()
path = path.rstrip(&#34;\\&#34;)
if os.path.exists(path):
print(f&#34;已经爬取该页面{movie_class}&#34;)
continue
else:
os.makedirs(path) (七)针对每部电影,获得其前十个影评网页的url
# 爬取每一部电影前10页的电影评论,共计200条
for url in urls:
if os.path.exists(os.path.join(path, f&#34;{url[1]}_200条影评.txt&#34;)):
print(f&#39;《{url[1]}》已经爬取&#39;)
continue
# 获得这部电影下前十页的影评网址
comment_urls = []
head_url = url[0] + &#39;comments?limit=20&status=P&sort=new_score&#39; # 影评网址首页
comment_urls.append(head_url)
for i in range(20, 201, 20):
other_url = url[0] + f&#34;comments?start={i}&limit=20&status=P&sort=new_score&#34;
comment_urls.append(other_url) # 后续9个影评网页在第五步的基础上,获取每部电影下面十个影评网页,存在comment_urls列表中
(八)针对每个影评网页爬取数据并保存到文件夹中
# 爬取所有的200个影评并保存到对应文件
print(f&#34;===开始爬取电影《{url[1]}》的200条影评===&#34;)
for comment_url in comment_urls:
response = requests.get(comment_url, headers=headers, proxies=proxies)
time.sleep(1) # 限制次数,防止被封ip
response.encoding = &#39;utf-8&#39;
response = response.text
# 定位到评论所在的地方
soup = BeautifulSoup(response, &#39;html.parser&#39;)
comments = soup.select(&#34;#comments&#34;)
try:
comments_ = comments[0].find_all(&#34;span&#34;, class_=&#39;short&#39;)
except IndexError:
continue
# 存放最终一条条评论
final_comments = []
for comment in comments_:
final_comments.append(comment.text.strip())
# 写入文件夹
with open(os.path.join(path, f&#34;{url[1]}_200条影评.txt&#34;), &#39;a&#39;, encoding=&#39;utf-8&#39;) as f:
for comment in final_comments:
f.write(comment + &#39;\n&#39;)
print(f&#34;===电影《{url[1]}》的200条影评爬取完毕===&#34;)
time.sleep(5) 4.爬虫全部代码(***着急的话可直接快进至此***)
# coding: utf-8
# 作者(@Author): 榕城候佳人
# 创建时间(@Created_time): 2022/11/7 19:02
# 修改时间(@Modified_time): 2022/11/17 17:30
&#34;&#34;&#34;
爬取豆瓣电影评论
&#34;&#34;&#34;
import requests
from bs4 import BeautifulSoup
import os
import time
# UA伪装
headers = {
&#39;User-Agent&#39;: &#39;Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36&#39;,
}
# 主网页
url = &#39;https://movie.douban.com/chart&#39;
# 设置代理,
proxies = {
# &#39;http&#39;: &#39;172.30.6.14:8880&#39;,
# &#39;http&#39;: &#34;36.152.44.96:5000&#34;, # 百度ip
# &#34;http&#34;: &#39;111.30.144.71:5000&#39;, # QQip
# &#39;http&#39;: &#39;47.103.24.173:5000&#39;, # b站ip
# &#39;http&#39;: &#39; 192.168.210.53:5000&#39;, # 本地ip
# &#39;http&#39;: &#39;60.205.172.2:5000&#39;, # CSDNip
&#39;http&#39;: &#34;49.233.242.15:5000&#34;, # 豆瓣ip(doge,想不到吧)
# &#39;http&#39;: &#39;120.233.21.30:5000&#39;, # 微信ip
# &#39;http&#39;: &#39;103.41.167.234:5000&#39;, # 知乎ip
# &#39;http&#39;: &#39;39.156.68.154:5000&#39;, # hao123ip
# &#39;http&#39;: &#39;36.152.218.86:5000&#39;, # 凤凰网ip
# &#39;http&#39;: &#39;151.101.78.137:5000&#39;, # 人民网ip
# &#39;http&#39;: &#39;221.178.37.218:5000&#39;, # 中国网ip
}
# 解决乱码问题
response = requests.get(url, headers=headers, proxies=proxies)
response.encoding = &#39;utf-8&#39;
# 获得不同类型电影的url
response = response.text
main_soup = BeautifulSoup(response, &#39;html.parser&#39;)
dif_movies = main_soup.select(&#39;#content > div > div.aside > div:nth-child(1) > div&#39;)
movie_types = [] # 存储不同类型电影的页面url
urls = dif_movies[0].find_all(&#39;a&#39;)
# 获得不同类型电影的代号和名称
for url in urls:
param = url[&#39;href&#39;]
index1 = param.find(&#34;&type=&#34;)
index2 = param.find(&#34;&interval_id=&#34;)
type_num = param[index1 + 6:index2] # 电影类型代号
type_name = param[20:index1] # 电影类型名称
movie_types.append((type_num, type_name))
# 爬取不同类型电影中前15的电影评论
for type, movie_class in movie_types:
print(f&#34;{&#39;*&#39; * 20}开始爬取->{movie_class}<-类型的电影{&#39;*&#39; * 20}&#34;)
movie_url = &#39;https://movie.douban.com/j/chart/top_list&#39;
param = {
&#34;start&#34;: &#34;0&#34;,
&#34;limit&#34;: &#34;20&#34;,
&#34;type&#34;: f&#34;{type}&#34;,
&#34;interval_id&#34;: &#34;100:90&#34;,
&#34;action&#34;: &#34;&#34;,
}
response = requests.get(movie_url, headers=headers, params=param, proxies=proxies)
time.sleep(1) # 限制请求时间,防止被封ip
response.encoding = &#39;utf-8&#39;
movie_data = response.json()
# 存放这个类型下前二十的电影的网址和名称
urls = []
for data in movie_data:
urls.append((data[&#39;url&#39;], data[&#39;title&#39;]))
# 创键对应的电影类型目录
path = os.path.join(&#34;E:\PycharmProjects\Web项目\新传数字人文项目&#34;, movie_class)
path = path.strip()
path = path.rstrip(&#34;\\&#34;)
if os.path.exists(path):
print(f&#34;已经爬取该页面{movie_class}&#34;)
continue
else:
os.makedirs(path)
# 爬取每一部电影前10页的电影评论,共计200条
for url in urls:
if os.path.exists(os.path.join(path, f&#34;{url[1]}_200条影评.txt&#34;)):
print(f&#39;《{url[1]}》已经爬取&#39;)
continue
# 获得这部电影下前十页的影评网址
comment_urls = []
head_url = url[0] + &#39;comments?limit=20&status=P&sort=new_score&#39; # 影评网址首页
comment_urls.append(head_url)
for i in range(20, 201, 20):
other_url = url[0] + f&#34;comments?start={i}&limit=20&status=P&sort=new_score&#34;
comment_urls.append(other_url) # 后续9个影评网页
# 爬取所有的200个影评并保存到对应文件
print(f&#34;===开始爬取电影《{url[1]}》的200条影评===&#34;)
for comment_url in comment_urls:
response = requests.get(comment_url, headers=headers, proxies=proxies)
time.sleep(1) # 限制次数,防止被封ip
response.encoding = &#39;utf-8&#39;
response = response.text
# 定位到评论所在的地方
soup = BeautifulSoup(response, &#39;html.parser&#39;)
comments = soup.select(&#34;#comments&#34;)
try:
comments_ = comments[0].find_all(&#34;span&#34;, class_=&#39;short&#39;)
except IndexError:
continue
# 存放最终一条条评论
final_comments = []
for comment in comments_:
final_comments.append(comment.text.strip())
# 写入文件夹
with open(os.path.join(path, f&#34;{url[1]}_200条影评.txt&#34;), &#39;a&#39;, encoding=&#39;utf-8&#39;) as f:
for comment in final_comments:
f.write(comment + &#39;\n&#39;)
print(f&#34;===电影《{url[1]}》的200条影评爬取完毕===&#34;)
time.sleep(5) |
|


 发表于 2022-12-3 19:24:57
发表于 2022-12-3 19:24:57